近几年的AI浪潮之下,端侧AI成为一个重要的发展分支和方向,凭借隐私保护、数据安全、成本控制、空间友好等方面的优势得到了越来越广泛的应用。为此,各家厂商纷纷打造了各种各样的端侧AI硬件方案,比如苹果Mac mini、AMD Strix Halo、NVIDIA DGX Spark,都以迷你机的形态,提供了强大的算力和丰富的开发用户应用生态。
那么,Intel呢?

其实,Intel有着更为丰富的端侧AI硬件方案,远超其他任何友商,包括AI PC轻薄本、AI高静游戏本、AI台式机、Mini AI工作站、AI工作站、边缘/车载AI Box、AI NAS等等。它们基于酷睿Ultra或者至强W处理器,可搭配核显、独显乃至锐炫Pro专业显卡,满足端侧通用、垂直行业、边缘计算等众多领域的不同需求。

日前在重庆举办的技术创新与产业生态大会上,Intel就集中展示了以旗舰型号酷睿Ultra 9 285H为代表的酷睿Ultra 200H系列的四大全新AI能力,包括:更大的系统内存、更大的共享显存、更多的应用场景、更多的产品选择。


酷睿Ultra 200H系列最高可以支持128GB系统内存,最高频率LPDDR5X-8400或者DDR5-6400。
面向8000元以下价位段的主流市场,Intel推荐采用酷睿Ultra 9 285H处理器搭配64GB内存,专业、日常全场景需求都能满足。针对万元价位以上价位段的发烧友、开发者市场,Intel推荐采用酷睿Ultra 9 285H处理器搭配96GB或128GB内存,带来更强的AI算力。由于目前内存的价格实在离谱,第一批次产品的内存容量基本都是最高96GB。
值得一提的是,酷睿Ultra 9 285H处理器的整体AI算力高达99 TOPS,其中iGPU 77 TOPS ,可确保大参数AI模型流畅运行,NPU 13 TOPS,专为高能效AI推理设计,CPU 9 TOPS,可保障系统快速响应与低时延处理。
不同于友商,Intel阵营的产品形态更加丰富,不止有迷你机,还有笔记本,而且都是品质更高的商用本甚至工作站级笔记本。现场展示的首批产品,包括:华硕NUC15 Pro、零刻GTi15、创盈芯A3A、极摩客EVO-IT、机械师MiniGTS、六联MTB19D、Geekom NUCAR01-C包括戴尔Pro Max 16、惠普战99 16 Gli、联想昭阳悦Plus 16IAH等等。
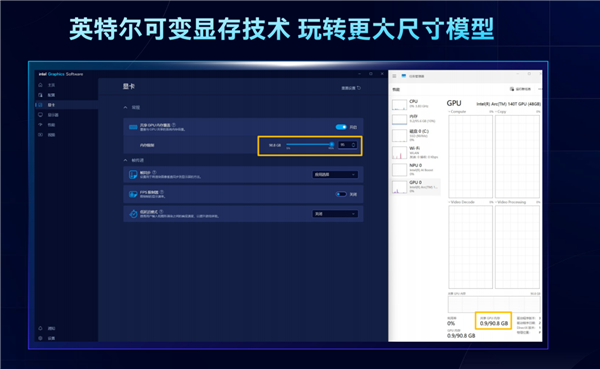
AI不但需要大内存,更需要大显存,AMD做到了96GB,NVIDIA做到了100GB,Intel则更加灵活、强大。
在Intel显卡驱动控制中心,开启“共享GPU内存覆盖”,就可以自由选择共享显存的比例,最少为系统内存的5%,最多可达95%。
也就是说,如果你的系统内存为128GB,最多可以共享120GB作为显存,96GB系统内存则能共享90GB,这是其他厂商都做不到的。




有了如此海量的显存,最直接的好处就是能够以更快的速度、运行更大参数量的大模型,从而用于更多的应用和场景,最高甚至能轻松搞定1200亿参数规模的MoE专家模型。
Intel现场演示了本地运行GTP-OSS-20B、Qwen3-30B-A3B、Qwen3-Next-80B-A3B、GTP-OSS-120B等不同参数量的MoE专家模型,逐步上强度,都轻松搞定。
最关键的是,Tokens生成速度相当快,并非每秒几个勉强能跑的样子,而是都达到了几十个、十几个,输出速度超过了人的阅读速度。

AI续写《红楼梦》也非常有意思,只需给出设定条件,AI就能洋洋洒洒一挥而就,很快就能写出几千字的情节,颇有阅读性和戏剧性。

Intel率先支持并优化了DeepSeek-R1 OCR模型,它拥有先进的光学压缩技术,可以准确处理文档资料,并支持更长的内容。
在酷睿Ultra 200H系列高算力的支持下,能够精准识别图像中的文字与排版格式,一键转换为可编辑文档,不但输入处理速度更快,还能显著降低内存消耗,并大幅提升识别效率与系统响应能力。
无论是复杂多变的扫描文档,还是带有各种图表的题目,抑或格式复杂的表格,都不在话下。
对于医疗处方影像、法务合同文书、培训学习教材、财会报销票证、学习笔记资料,这些需要内部保密,不方便上云处理的,更适合在本地端侧搞定,离线也不影响。

TTS文字转语音领域,无论是语音合成、声音克隆,还是多语言支持、多音色定制不在话下,在本地生成具有自然音色、节奏、情感的语音,实现个性化声纹的定制。
在端侧运行,更能保证个人声音不至于外泄而被恶意利用。
目前,Intel已经与众多TTS模型进行了合作,包括FastSpeech2、FireRedTTS2、GPT-Sovits、MeloTTS、OpenVoice2、Paler-TTS、Speech-t5、voxCPM-0.5B,等等。

视觉语言理解方面,可以实现“慧眼”识物。
酷睿Ultra 9 285H支持用户上传图片或者通过多个摄像头,采集图片和视频,在借助内置模型实时解析画面内容,提供即时反馈。
得益于Intel XPU架构的深度优化,首字生成速度得以大幅提升,从而带来更流畅、更直观的视觉交互体验。

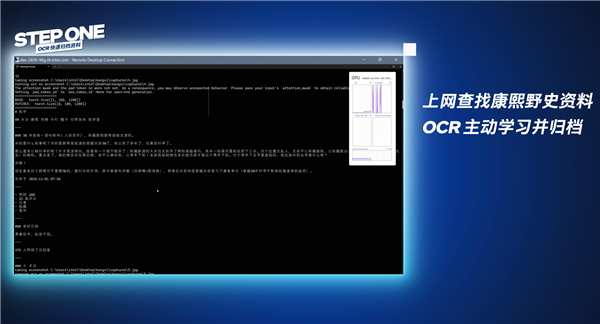
当然,我们还可以将OCR、LLM、MCP、TTS、I2V等多种能力组合在一起,处理更加复杂的任务。
酷睿Ultra 200H系列通过支持模型上下文协议(MCP),可赋予AI智能体强大的理解、记忆与执行能力,能够基于环境感知进行连续任务处理,让AI真正可以独立规划、连续执行。
比如最近非常火的“康熙之父野史”,AI就能快速生成相关视频,其中就包括OCR归档资料、本地模型整理资料、重点内容生成PPT、模仿音色完成配音、AIGC视频生成等用到了不同能力的多个步骤。
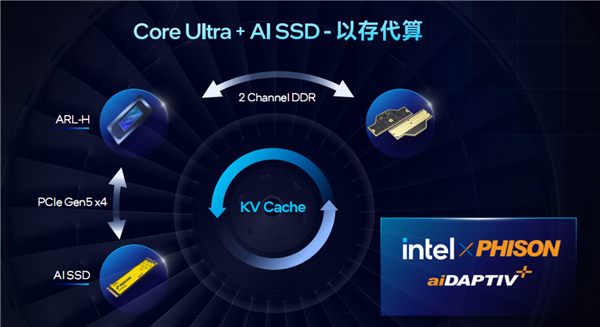


Intel与群联电子共同将aiDAPTIV+技术与酷睿Ultra 200H系列处理器结合,通过PCIe 5.0 AI SSD实现“以存代算”,显著加速模型推理。
aiDAPTIV+是群联电子、MaiStorage联合开发的AI技术,专为Intel AI PC平台优化,通过将闪存纳入AI系统存储池,将无需放在内存中的数据卸载至SSD,从而实现低预算生成式AI训练与推理,推理性能比核显高出10多倍,程序响应时间则可从73秒缩短至4秒。
这一技术不仅可以支持更快的响应速度、更长的长下文、大幅缩短响应速度,还能够以更低的投入,提供更快速、流畅的端侧AI体验。

如果这些还是不能满足你,还可以通过40Gbps带宽的雷电4或者80Gbps带宽的雷电5接口,进行双机互连,构建一个经济、高效的本地算力集群,乐趣加倍!
有了两颗酷睿Ultra 9 285H处理器、192GB甚至是256GB内存,就可以玩转更大的模型,MoE模型甚至能搞定235B也就是2350亿参数规模。
还可以通过双机DP模式,满足更多的并发用户,或者双机分别运行不同模型,支持更加复杂的应用场景。



另外,针对有着更高需求的专业用户、中小企业、工作室,Intel最近还推出了锐炫Pro B60专业显卡,搭配酷睿Ultra或者至强W处理器,可组成更强大的工作站,支持单卡、双卡、四卡、八卡甚至是多块双芯卡的不同组合,还可以搭配Gaudi AI加速器。
锐炫Pro B60就是为AI推理而生,基于Xe2微架构,拥有20个Xe核心、24GB大显存,带宽456GB/s,峰值算力197 TOPS。
还有低一档的锐炫Pro B50,面向图形工作站,拥有16个核心、16GB显存、170 TOPS峰值算力。







目前已有华擎、蓝戟、撼与、傲世、铭瑄、Senao、Lanner等多家厂商推出了不同形态的锐炫Pro B60/B50显卡,包括MXM迷你卡、半高式刀卡、无风扇被动散热等。
铭瑄、撼与更是打造了双芯的锐炫Pro B60,单卡就有48GB显存,八卡并行就有恐怖的384GB!
基于锐炫Pro B系列显卡的工作站方案,也正在不断涌现。

凭借酷睿Ultra 200H系列处理器、锐炫Pro B60专业显卡,Intel正在打造令人耳目一新的端侧AI硬件平台方案,灵活满足多行业多领域的不同需求,并且不断优化,拥有更丰富的AI能力。
明年,随着酷睿Ultra 300系列(Panther Lake)处理器的问世,随着性能、能效的再次飞跃,相信Intel还会带来更多惊喜玩法!
- 本文固定链接: http://wx.x86android.com/articles/6138.html
- 转载请注明: zhiyongz 于 安卓之星 发表